
CC BY 4.0 (除特别声明或转载文章外)
GAN Overview


Generator
Discriminator
Basic Idea of GAN

Algorithm



Theory behind GAN

由于我们不知道$P_G$和$P_{data}$的具体分布,所以不能直接计算两个分布的差异,但是我们可以在两个分布中采样,然后计算两个分布采样出的结果的 Divergence
JS divergence 是描述两个概率分布的差异的一种方法,Discriminator 的目标是鉴别目标到底是真实数据还是 Generator 产生的数据,所以它要给真实数据一个较高的分数,给 Generator 生成的数据一个较低的分数,所以 Discriminator 要让真实数据和 Generator 得到的数据的 JS divergence 最大。但是 JS divergence 作为 loss function 的时候比较复杂,而数学证明$V(G, D)$与 JS divergence 之间具有一定的关系,所以在训练 Discriminator 的时候采用的是$V(G, D)$,我们只需要找到$max V(G, D)$


Other Divergence

Tips for GAN
The problem of JS divergence

JS divergence 并不适合用来衡量两个分布的差异,因为:
- 考虑数据的特性,$P_{data}$和$P_G$都是高维空间的低维流形(拿生成动漫头像为例子,动漫头像就是处于一个$pixel \times pixel \times channel$这样高维度空间中的一小部分具有某些特征的空间,就是一个低维度镶嵌在一个高维度的一个特定空间,它不具有高维度空间的性质),所以他们有 overlapped 的几率是很小很小的,几乎可以看作没有重叠,所以 JS divergence 很难进行下去。
- 就算有一定的 overlapped 的部分,但是我们还要进行采样,如果我们的样本不是很多的话,也算没有重叠。


Wasserstein distance





Conditional Generation
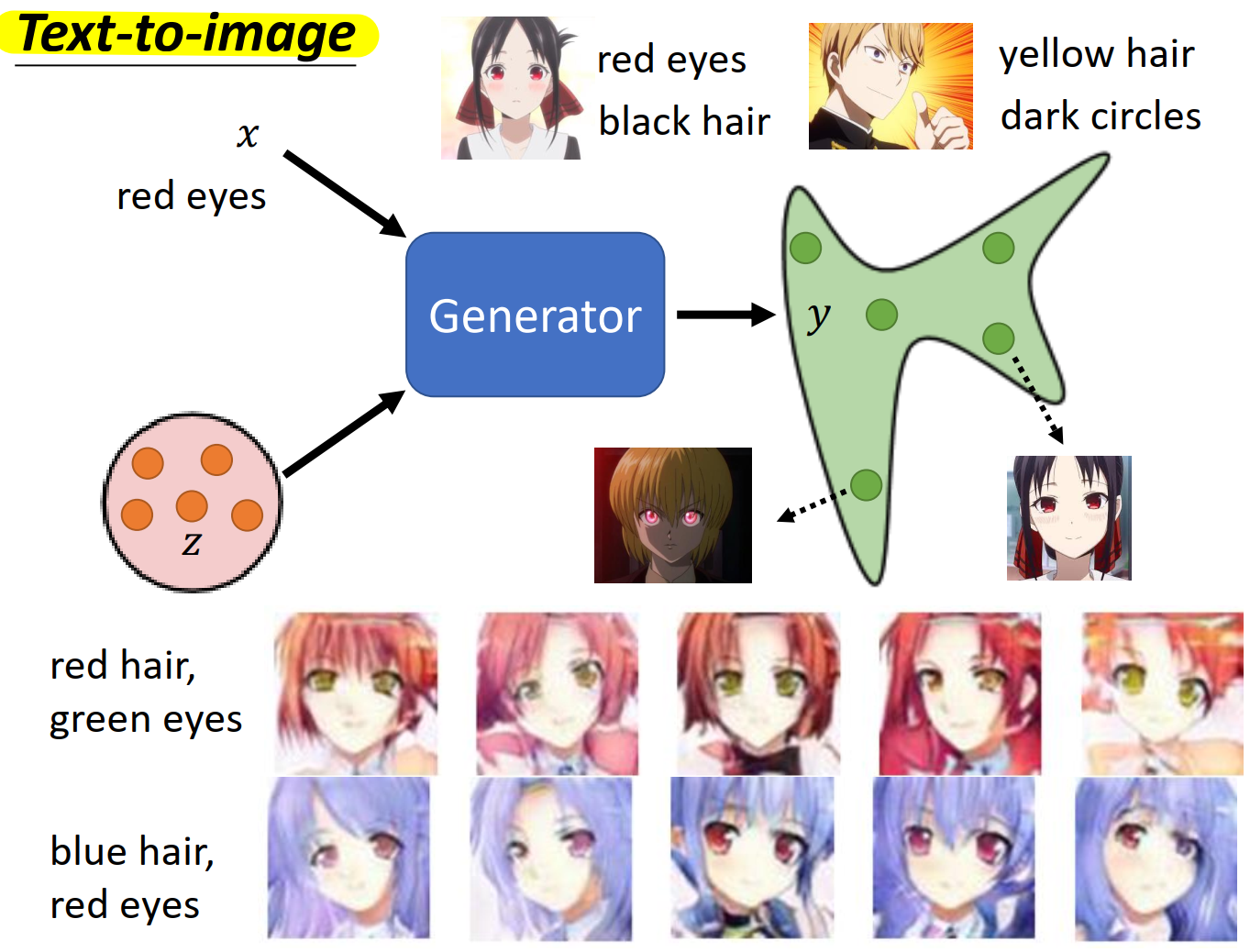
训练数据是成对的数据(text-image pairs)有图片和图片的文字描述
Applications 除了 Text-to-image 之外还有……





Learning from Unpaired Data


Cycle GAN


StarGAN
Other Unpaired Data Applications


Evaluation of Generation
我们怎么评估 GAN 生成出来的图像质量呢?使用人力的话,耗费巨大不说而且难以让人信服。我们可以采用图像分类的神经网络,它的输出就是一个 distribution 的所有 class 的概率,如果某一个 class 的概率很高,远高于其他 class 的概率,我们就可以认为 GAN 生成的图像质量较高,反之说明 GAN 生成的图像质量较低。
但是,使用上述方法对 GAN 生成的图像进行判断的时候,会存在以下问题……
Mode Collapse
如果 GAN 产生的图片质量确实很高,图像分类的结果也很明显,但是它翻来覆去就那几张图片,没有多样性,这个问题叫做 Mode Collapse。 
Mode Dropping
如果 GAN 生成的图片虽然质量高而且有多样性,但是它只学习了样本的一部分特征,生成的图片在某一个特征上都一样(e.g. 下图中产生的图片肤色要么偏白,要么偏黄,在肤色在一个特征上所有生成的图片都差不多,这显然不是我们想要的,但是利用图像分类来评估 GAN 的结果是无法发现这个问题的),这个问题叫做 Mode Deopping。
Inception Score
当然,Mode Collapse 和 Mode Dropping 也不是没有办法解决,我们可以同时考虑生成图像的质量和生成图像的多样性,对生成的所有图像计算多样性,对生成的单个图像看图像分类 class 的概率。
FID
训练一个 CNN 网络,把真实图片和生成的图片都放入 CNN 网络,将它们的进入 softmax 前一层隐层中的分布拿出来计算距离,距离越小代表越相似