
CC BY 4.0 (除特别声明或转载文章外)
Applications

Speech Translation


Text-to-Speech(TTS) Synthesis

Chatbot

Natural Language Processing


Syntactic Parsing

Multi-label Classification

Object Detection

Transformer

Encoder



Decoder
Decoder – Autoregressive (AT)


 Masked Self-attention 就是计算$\alpha ^ {‘}$时只考虑现输入和以前的输入,因为 Decoder 的时候$\alpha_1,\alpha_2,\alpha_3,\alpha_4$一个一个产生的,所以在计算$\alpha^{‘}$时只能考虑现输入和以前的输入
Masked Self-attention 就是计算$\alpha ^ {‘}$时只考虑现输入和以前的输入,因为 Decoder 的时候$\alpha_1,\alpha_2,\alpha_3,\alpha_4$一个一个产生的,所以在计算$\alpha^{‘}$时只能考虑现输入和以前的输入



Decoder – Non-autoregressive (NAT)

Cross attention



Training
训练过程


训练的 Tips
Copy Mechanism


Guided Attention

我们训练的时候强制让它从左到右计算 Attention weights
Beam Search
Beam Search 可以找到分数最高的路径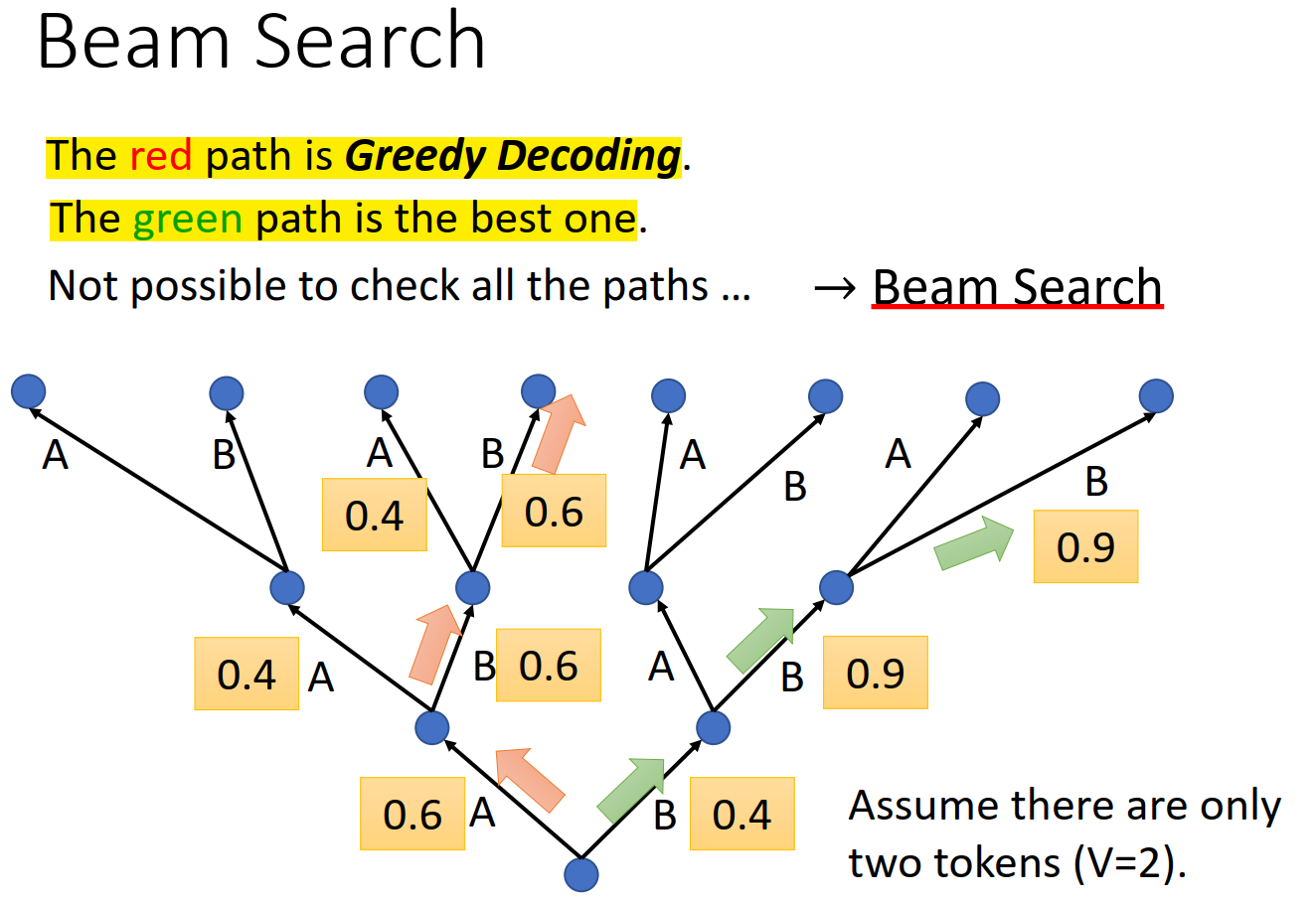
而有一些需要机器具有一定的创造性的任务 Beam Search 就不一定有好的效果了,(e.g. sentence completion, TTS),这时候我们就期待 Decoder 具有一定的随机性

Scheduled Sampling
由于测试的时候 Decoder 是看着它自己的前一个输出然后输出后一个,如果 Decoder 输出了一个错误的答案,那么 Decoder 很有可能就是一步错,步步错,因为我们训练的时候 Decoder 看到的都是完全正确的情况,所以为了解决这个问题,我们可以在训练的时候就加入一些错误,反而能得到好的训练结果
